
Should AI Review Your Pull Requests? Probably. By Ed Lyons

Image crated by Ed Lyons with Midjourney
There is a lot of talk about AI being used to help individual coders inside their development environments. Now we are seeing AI tools for reviewing pull requests. Is this the same thing? No. Even though these newer tools use the same underlying technology, a pull request to be reviewed by the team is its own institution in software development, one that is primarily about engineering, yet it involves human considerations.
Should you welcome generative AI into your discussion about someone’s contributions to your project? You probably should.
Using a new AI PR review tool from Code Rabbit, I did an evaluation of its capabilities. (This tool works in GitHub, but I predict this feature will soon be available in many products that host repositories and allow PRs.)
For the evaluation, I decided to find two public projects in Github that I have experience with, and use those codebases to create pull requests.
The first is coverage.py, the most well-known code coverage tool for testing in Python. It has been written almost entirely by Ned Batchelder, a careful and very senior Python developer who is highly respected in the Python community.
The second is a performance dashboard by an advocacy group that tracks how well the mass transit system works in Greater Boston. It was built by a group of volunteer developers of various skill levels, and it is mostly in Typescript.
In each case, I forked each repository, I then created branches from various stages of development over the past few years, and then I created pull requests using newer branches to merge against earlier versions.Then I used the trial version of Code Rabbit to evaluate the changes.
In all reviews, Code Rabbit provided an in-line summary of changes made in the PR, which look like this:
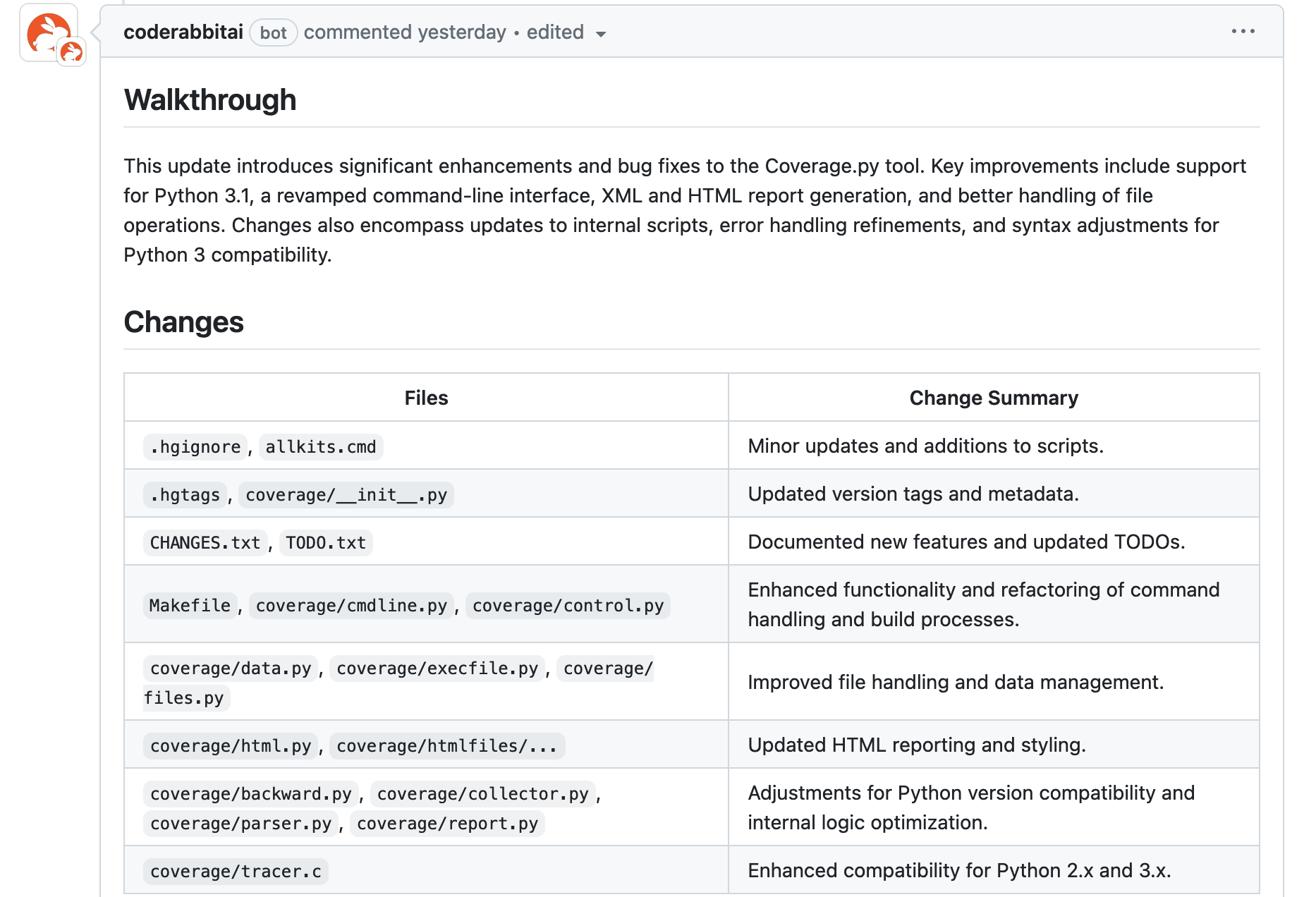
Summarizing is a great strength of AI, and the code reviews show it. These summaries aren’t better than what a person could write, but they seem good enough to automate descriptions of what changed in your PR.
Looking at a few PRs for coverage.py, the findings were sparse and mostly reported what traditional static analysis tools provide: recommendations according to coding standards.
An example is here:

Notice that when the tool thinks it can give you the commit to make the change, it does.
There was one substantial comment. It didn’t like the use of a callback function, as seen below:

I don’t think this leads to any valuable action item, but it is the kind of thing you often see in human code PR review comments: the reviewer would have done something differently.
In general, I was unimpressed with the reviews for coverage.py code changes over time. There was even a comment that misidentified what the code was doing, and recommended a change that would have had no effect.
However, the reviews for the transit project were more valuable.
It still had many comments around coding standards. But there were two new kinds of comments: handling edge cases and using other approaches.
Some of the comments pointed out potential problems needed to be handled, such as an expected piece of data not being there, or a problematic state of a visual component. These concerns were valid, and are typical feedback items in human PR reviews.
Other times, Code Rabbit pointed out that a different approach was better, such as this recommendation to use React Router:
There was also a comment that a lone shell script used formatting characters that were out-of-date, and did not handle unusual situations. This is a common problem. Good programmers can dabble in other languages in a project for simple tasks, and they might not be as skilled in those languages. The AI can catch these little things that might get overlooked while everyone is looking at new features and bug fixes in the PR.
The differences between the reviews for the code coverage tool and the transit dashboard are illuminating.
Coverage.py is a slow-moving project done almost entirely by a master programmer. He follows best practices by habit. For him, there isn’t much to be gained from the AI reviews that he wouldn’t get out of existing, inexpensive static analysis tools.
The transit dashboard has a large team of varied experience that adds significant new features over time, and the project moves much faster. For them, there is a lot more that AI can see and recommend that could be useful.
Code Rabbit also has case studies on its website that demonstrate other types of valuable feedback. One shows in-line communication through comments asking for help and clarifications that the AI will answer. A good example of that can be found here.
But even for a team that needs what the AI reviews can provide, what about the human factors? Though I could not test them, I can imagine some potential benefits to having an AI that doesn’t care about all the things that can make PRs contentious.
In human teams, perhaps someone does not want to point out a different way of doing something, even if it is better, as they are a more junior person commenting on work done by someone more experienced. Or going the other way, perhaps one team member does not want to make even more critical comments than they have already for the PR of the new person.
Perhaps AI reviews will bring up issues that might not otherwise be discussed, and developers will seek safety in the AI’s comments. It is easy to imagine someone saying, “Look, the AI said we aren’t handling this correctly. Now I wouldn’t have gone that far, but maybe there is something we should be talking about.”
As this technology advances, perhaps there will be options in terms of what it reviews, its simulated personality, or what its architectural preferences are. Maybe your team needs a detailed-oriented member, or someone who is overly paranoid about rare errors. Or even someone who is more of a teacher for junior developers and is accepting of less elegant code. It is fun to think about what this might look like.
But even now, this technology feels like a good addition to PR reviews. If it can prevent errors, recommend more proven approaches, and get some discussions happening that would not have happened otherwise, most teams would probably see benefits.