
ODSC East 2024: A Crowded Marketplace of Powerful, Risky AI Language Models by Ed Lyons
Image cc-1.0 via Awesome LLMs
When Open AI showcased ChatGPT to the public a little more than a year ago, they promised their general purpose AI would continue to expand in capabilities, and eventually solve many of humanity’s great problems. We learned that the cost of developing and running such a god-like model was extraordinary, and beyond the means of all but a few companies. We would all have to just pay to use this technology as a service, it appeared.
But that was not what happened.
Thanks to Meta and other companies releasing open models for others to use, as well as many new players specializing in pieces of the architecture, instead of waiting for OpenAI to succeed at becoming all things to all people, we now have a large, loud, chaotic marketplace full of booths and buskers, each boasting of the usefulness of their models, at costs so varied, it is hard to know whom to believe.
There are now many websites that show the breadth of offerings, such as on the model page of the AI community site Hugging Face, which shows not only great numbers, but many categories:
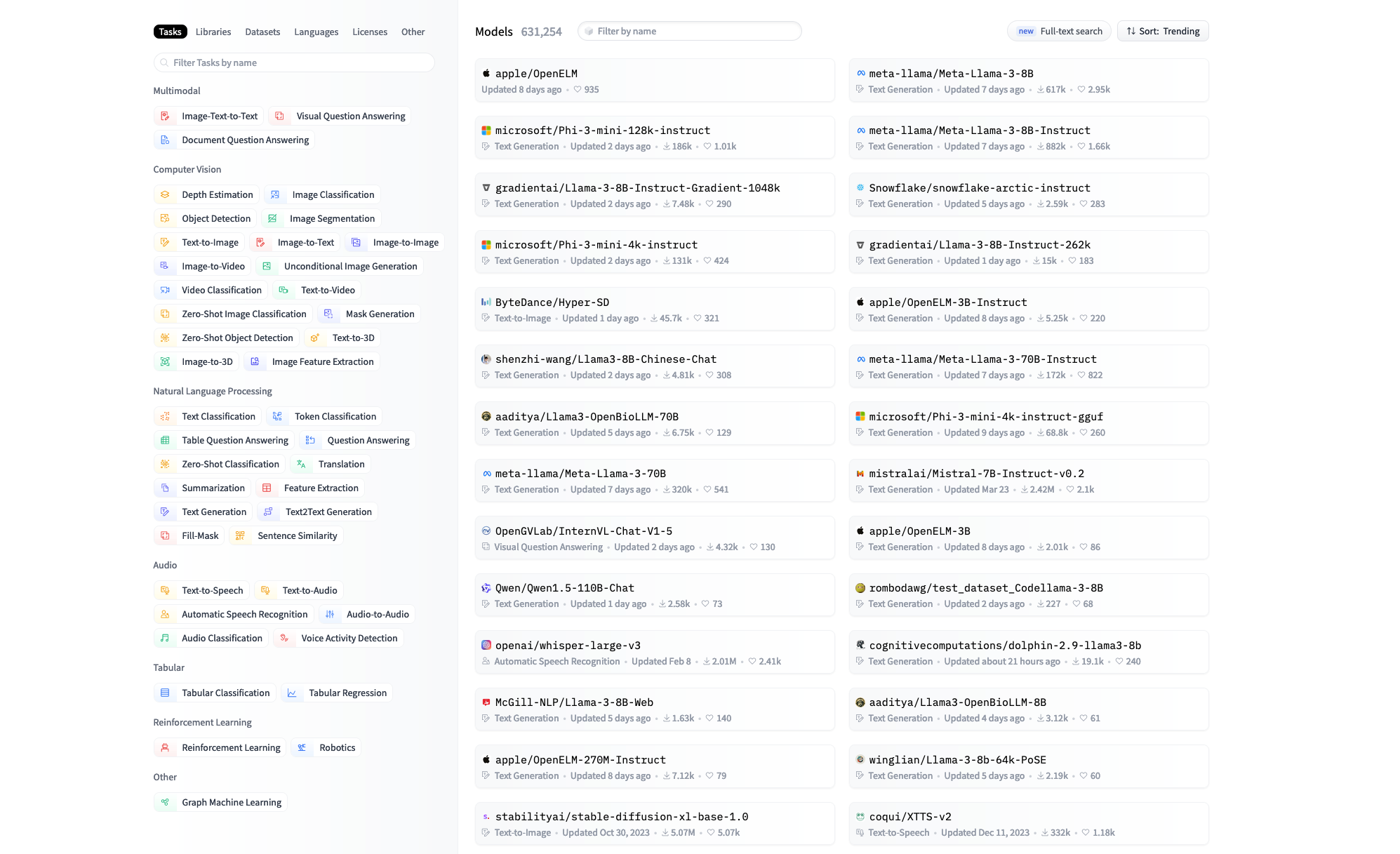
At the 2024 ODSC East conference, my fellow EQengineered co-workers and I saw this new reality, where choosing a large language model for your organization is now a complex exercise, with significant downstream costs, and many risks. The costs of hosting, training, tuning, and monitoring such huge and complex models can vary enormously. It is more like choosing a CRM platform or cloud provider than choosing a framework to be used by developers.
Yet the opportunities for organizations that had previously thought they could only subscribe to the services of much larger firms are now too great to ignore.
The good news is that there are small, open, inexpensive models that can be used for experimentation without consulting senior management.
For example, at the conference, we saw an enlightening tutorial, run on a free coding platform called Google Colaboratory (called ‘Colab’ by users), that used a GPT-2 model to show how customizations can work. This was demonstrated on cheap cloud-based hardware. Of course, it wasn’t nearly as sophisticated as much larger, more costly models. Yet putting this smaller model through various tasks was a great way to learn about how models can be manipulated and improved. Understanding the lifecycle and customization points is an important part of using this technology for your organization.
Other sessions that evaluated models came to a surprising conclusion: bigger and more costly models often do less well than a smaller one that is better suited to your needs, especially if you have fine-tuned it using your own data. It is tremendously inefficient and expensive to purchase a model powerful enough to be all things to all people in order to be what only you need. In addition, choosing a large model instead of a smaller one can dramatically increase the costs of hosting and customizing it.
With so many options, what kinds of questions must be answered before making a choice?
Here are a few:
What type of model best suits our specific needs?
How much would it cost for all phases of development, enhancement, and operation?
Has the training it has gone through relevant to our business?
Do we have to do additional training of this model?
How secure would our data be if we added it to the model?
How will errors and other unacceptable outputs be managed?
How can we integrate this into our larger architecture?
It is a relief to know this technology can be cheaper and more customizable that it appeared to be a year ago. However, the emerging marketplace is intimidating and confusing. Fortunately, as we saw at the conference, there are many inexpensive models to experiment with, and communities full of people with experience to share.