
Modern Data Architecture - A Data Modernization Green Paper by Ranjan Bhattacharya

Executive Summary
Organizations have been collecting, storing, and accessing data from the beginning of computerization. Insights gained from analyzing the data enable them to identify new opportunities, improve core processes, enable continuous learning and differentiation, remain competitive, and thrive in an increasingly challenging business environment.
The well-established data architecture, consisting of a data warehouse, fed from multiple operational data stores, and fronted by BI tools, has served most organizations well. However, over the last two decades, with the explosion of internet-scale data, and the advent of new approaches to data and computational processing, this tried-and-true data architecture has come under strain, and has created both challenges and opportunities for organizations.
In this green paper, we will discuss modern approaches to data architecture that have evolved to address these challenges and provide a framework for companies to build a data architecture and better adapt to increasing demands of the modern business environment. This discussion of data architecture will be tied to the Data Maturity Journey introduced in EQengineered’s June 2021 green paper on Data Modernization.
Introduction
Data storage has always been an integral part of computer technology. In the early days of commercial computing, the technology for storing and retrieving data was clunky and slow, and required users to become experts. In the 80s, with the introduction of relational databases, data storage and access started becoming easier for even non-experts to use.
A major transformation in the way organizations use data came about with the data warehousing paradigm in the early 90s. Business leaders could now access business intelligence dashboards from a centralized data store, fed from multiple operational data systems. Up to this point, the managing the various components of the data architecture was relatively straightforward for most organizations.
Over the last two decades, several transformative technology trends like the following have emerged in the business landscape causing foundational changes to business norms:
Internet-scale data generation and its impact on data volume, velocity, and variety,
The rise of cloud computing and its impact on scale and availability, and
Adoption of machine learning and artificial intelligence techniques for business analytics.
For companies to succeed in this transformed landscape, adoption of new technologies and architectures that align with strategic business priorities is imperative.
An Evolutionary Journey of Enterprise Data Architecture
Today, most organizations implement a variation of the following generic data processing flow and supporting processes and infrastructure:

The Enterprise Data Warehouse
The dominating data processing architecture of the 90s was the one that integrated operational systems with the enterprise data warehouse (EDW). The EDW forms the core component of business intelligence (BI), serving as a central repository of data from multiple sources, both current and historical.

This architecture enables an enterprise-wide capability for analytics and reporting, thus allowing organizations to respond quickly to changing business opportunities. For traditional organizational data-processing needs, this architecture can satisfy quality requirements like data integrity, consistency, availability, and failover. The flexibility of this architecture has also served well in the migration from on-premise installations to cloud.
Key Technological Trends and Architectural Shifts
The introduction of newer technologies and platforms like internet-scale systems, migration to cloud computing, ML/AI based analytics, IoT (Internet of Things), and edge devices like smart phones have necessitated fundamental shifts to the data architecture to meet the enhanced requirements for scalability, consistency, and disaster recovery.
The table below lists how enterprise data components are impacted due to this shift.

NoSQL Databases and Polyglot Persistence
Relational database technologies are well-suited for enterprise transaction processing with their ACID—atomicity, consistency, isolation, and durability—guarantees, which ensure data validity despite errors and failures. To implement these ACID properties, relational databases make some tradeoffs with regards to scalability and availability by assuming a single instance deployment, with tools for replication and disaster recovery. Handling a larger volume of data simply means running the database on a larger server.
Concerns about data consistency and availability were not part of mainstream enterprise architectural thinking before the confluence of several technological shifts like the widespread adoption of cloud computing to handle the increasing volume and variety of unstructured data serving a globally distributed user base. Companies quickly realized that simply moving a relational database to a larger server is not able to meet the scalability and availability demands of the business. Organizations need to think about distributing the load across multiple database instances. However, relational databases are not designed to guarantee availability in the face of network failures that is inherent in a distributed system.
In addition, modern Internet based applications generate a wider variety of unstructured data that can consist of images, audio and video data, chat transcripts, application logs, social media interactions, and other content that is difficult for relational technologies to handle.
A new class of database technologies, collectively known as NoSQL databases, better suited for distributed operations, and storing various forms of unstructured data, has become popular in the last decade.
The following table lists the different types of data and access patterns for which NoSQL databases are more appropriate.
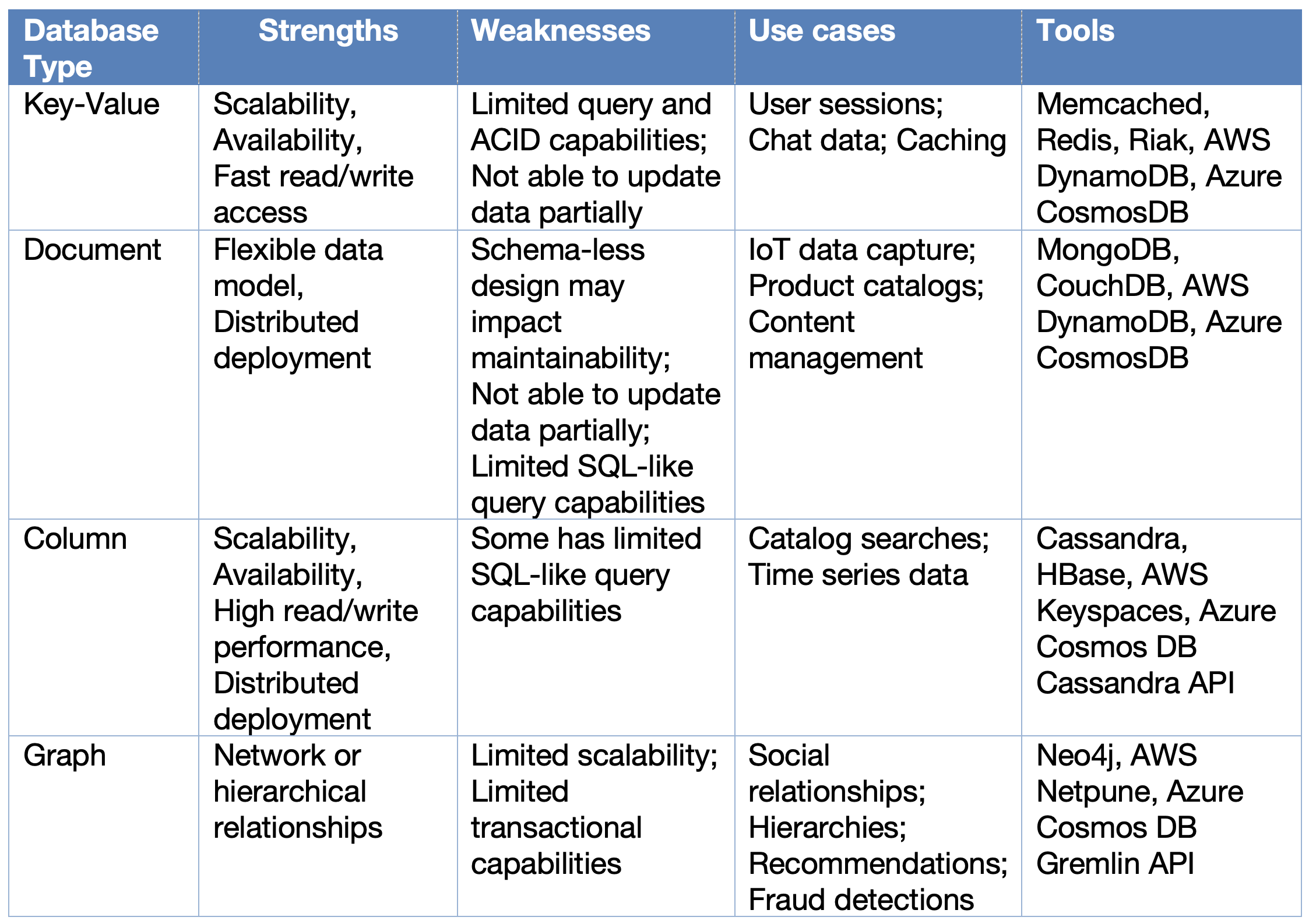
An organization may opt for a mix of different databases, with relational databases providing the core and critical transactional components of a system, while one or more of the NoSQL databases providing support for different use cases. This trend of picking the right database technology for the right use case has become known as polyglot persistence.
Data Lake and ELT
The needs of traditional analytics are well-met by the data warehouse architecture discussed above. Interactive BI dashboards, visualization tools, and reports can describe what is happening in a business, and answer questions like “What Happened?” and “Why did Something Happen?” These tools mostly deal with structured data, well-defined at source, and ingested through batch processes.
The ETL (Extract-Transform-Load) pattern has been the workhorse of ingesting data from diverse sources into the data warehouse for a long time.

The ETL pattern includes the following steps:
Extract: data is copied from different source systems to a staging area, typically in batch mode.
Transform: data cleansing, enrichment, and transformation is done in preparation for loading into the data warehouse
Load: the transformed data is loaded into the data warehouse tables
Although the ETL approach is good for bulk data movement, it has a few limitations in the new world of internet scale, real-time data, and AI/ML based analytics, including:
It is primarily batch-oriented and not suitable for real-time data
EDW schemas are difficult to change and adapt to changing source data structures
Data that does not have a schema defined for it cannot be loaded into the EDW and is not available to the analytics team
Since in this model the EDW serves as a repository of historical data, the data that cannot be loaded into the EDW is lost
For the data that is loaded into the EDW, its lineage information is not preserved
Because of the dependency on an EDW schema, unstructured and binary data are difficult to load
The ELT (Extract-Load-Transform) is a variation on the ETL approach, and it consists of the following steps:
Extract and Load: data is copied from different source systems to a centralized repository or staging area in its raw form, sometimes called a data lake
Transform: data from this central repository is moved after cleansing, enrichment, and transformation to the most appropriate location for analytics, which may be a data warehouse, or even a NoSQL database.

The advantages of this approach include:
Data is always maintained in its raw form in the data lake, preserving history and lineage information
Data from diverse sources—real-time, and streaming, structured, unstructured, and binary—can all be stored in the data lake
Data in the data lake can be processed after the fact when a need arises
Analytics tools can access data directly from the data lake even if it is not available in the data warehouse
Patterns for Building a Modern Data Architecture
In an earlier green paper—Building an Effective Data & Analytics Operating Model—we presented a data maturity journey:

As an organization plans on a data modernization initiative, selecting the appropriate set of technologies and tools from the breathtakingly diverse and complex choices may appear quite daunting. To select an architecture best suited for their specific needs, it helps to think in terms of the maturity journey, the appropriate use cases, and corresponding patterns of data architecture.

The important thing to note here is the recommendation to migrate to cloud-based data platforms which offers several advantages over using traditional on-prem technologies, including that it is easier to get started, scale, and mature.
Here is a list of popular cloud-based technologies used in the modern data architecture stack:

Architectural Pattern for Descriptive & Diagnostic Stage Analytics

The architectural pattern for descriptive and diagnostic stage analytics is appropriate for organizations of all sizes which are at the initial milestones of their analytics journey. It uses an architecture quite similar to that of the traditional EDW architecture, with a few enhancements.
The architecture includes the:
Ability to handle multiple data sources, both structured and some unstructured
Use of cloud-based technologies: relational databases for storing operational data, data warehouse, NoSQL data stores
Because of the similarity of this architecture to traditional EDW setups, it is easier to get started. Most importantly, however, this architecture lays the ground work for moving to the subsequent maturity levels of the data journey without requiring a major rearchitecting effort.
Architectural Pattern for Predictive Stage Analytics

The pattern for predictive analytics is the next milestone in the data maturity journey and is appropriate for organizations with more complex data needs, including support for more diverse data types, streaming data, and support for both operational and analytics use cases.
The salient components of this patterns include the:
Use of the ELT workflow and a cloud-based data lake to handle the diversity of source data
Use of prepackaged AutoML platforms for a relatively simple approach to predictive analytics
Architectural Pattern for Prescriptive Stage Analytics

At the end stage of the data maturity journey, the pattern for prescriptive analytics supports a robust MLOps workflow, with exploration, testing, deployment, and monitoring, with AI/ML as a core capability.
This architecture is both powerful and flexible to address the most sophisticated analytics needs of an organization.
Conclusion
Harnessing the capabilities of a mature data and analytics practice will allow organizations to create significant value and differentiate themselves from their competitors. There is a wide choice of tools from which to build a modern data architecture stack.
Though there is no one-size-fits-all approach, the above framework assists an organization to build a robust and adaptable data architecture aligned to their strategic and business imperatives.