
Data & Analytics Thought Leadership Series by Ranjan Bhattacharya

Executive Summary
This is the age of analytics—information resulting from the systematic analysis of data.
Insights gained from applying data and analytics to business allows large and small organizations across diverse industries—be it healthcare, retail, manufacturing, financial, or others—to identify new opportunities, improve core processes, enable continuous learning and differentiation, remain competitive, and thrive in an increasingly challenging business environment.
The key to building a data-driven practice is a Data and Analytics Operating Model (D&AOM) which enables the organization to establish standards for data governance, controls for data flows (both within and outside the organization), and adoption of appropriate technological innovations.
Success measures of a data initiative may include:
Creating a competitive advantage by fulfilling unmet needs,
Driving adoption and engagement of the digital experience platform (DXP),
Delivering industry standard data and metrics, and
Reducing the lift on service teams.
This green paper lays out the framework for building and customizing an effective data and analytics operating model.
Introduction
As companies digitize their business practices, new business models and technologies create vast amounts of data which offers the opportunity to gain strategic business insights.
Figure 1 below lists a number of key benefits that can accrue across the enterprise from a mature data and analytics operating model.

Figure 1: Benefits of a Data and Analytics Operating Model
With state-of-the-art tools, industry focus and strong business cases, it might be surprising that organizations often struggle to unlock the potential of data and analytics. However, data is only ever simple when viewed from the outside.
Turning business data into actionable intelligence is a journey with many challenges along the way. Just as the written word is notoriously open to ambiguities and interpretation, the world of data lives within overlapping nuances of real world-problem domains, software system behaviors, and the idiosyncrasies of data sets and their most outlying points of data. Truly meaningful analysis of data can be challenged by blind spots in any of these overlapping concerns. These challenges are compounded further when a system involves integrations between disparate sub-systems each with their own data sources, or when legacy schemas co-exist with modernized counterparts.
Since the challenges of data quality emerge from the entirety of a business, true data maturity is best thought of at an organizational level. It is critical to adapt business operations to the strategic vision of the business, while developing the right capabilities in terms of both technology and talent. It is not enough to just add a powerful technology layer to existing business processes.
Key operational gaps may exist in an enterprise in areas such as:
Data collection and sustained management,
Data hygiene and consistency,
Data governance and compliance,
Data security, and privacy, and/or
Adoption of data best practices, modern data architecture, technologies, and tools.
A Modern Data Ecosystem
The figure below portrays the high-level components of a modern enterprise data ecosystem.

Figure 2: A Modern Data Ecosystem
The main components of this data ecosystem can be described as:
Data generation and collection
Data aggregation
Data analysis
Data governance
In modern organizations, the volume, variety, volatility, and velocity of incoming data is breathtakingly diverse. Data can be derived from:
Structured data from databases, flat files, and other external systems via APIs,
Streaming data from real-time sources like mobile phones, wireless sensors, etc., and
Unstructured data from documents, chat transcripts, images, audio, and video sources.
The difficulties of interpreting unstructured data are more immediately apparent. However, even the most structured data, whether meticulously normalized relational databases or documents with exacting schemas, should be considered in relationship to the layers of real-world domains and underlying software. Fields prohibited from having missing data may end up with meaningless placeholder values in them, and seemingly clear datapoints may be interpreted counterintuitively behind the scenes by obscure software pathways. Users will often have unexpected understandings of the data which arise from industry-specific or even organization-specific usage customs.
Once the source data is collected, it must be cleaned, transformed, and loaded into various repositories. This may include Operational Data Stores or ODSs, enterprise or cloud-based data warehouses, NoSQL databases, or data lakes.
Only after this information is available in the repositories can insights and predictions be gleaned from the data. Common outcomes include:
Easy to consume interactive reports and dashboards using reporting and business intelligence tools
Patterns and predictions using tools and techniques of data mining, artificial intelligence (AI), and machine learning (ML).
Coupled to this end-to-end data pipeline, should be a governance structure, spanning business and technology with policies around master data management, data handling ethics, data quality, security, and privacy.
The Data Analytics Maturity Journey
To help assess where an organization is on its data journey, it is helpful to look at a widely used maturity curve adapted from Gartner.
The X and Y axes represent maturity and business value.
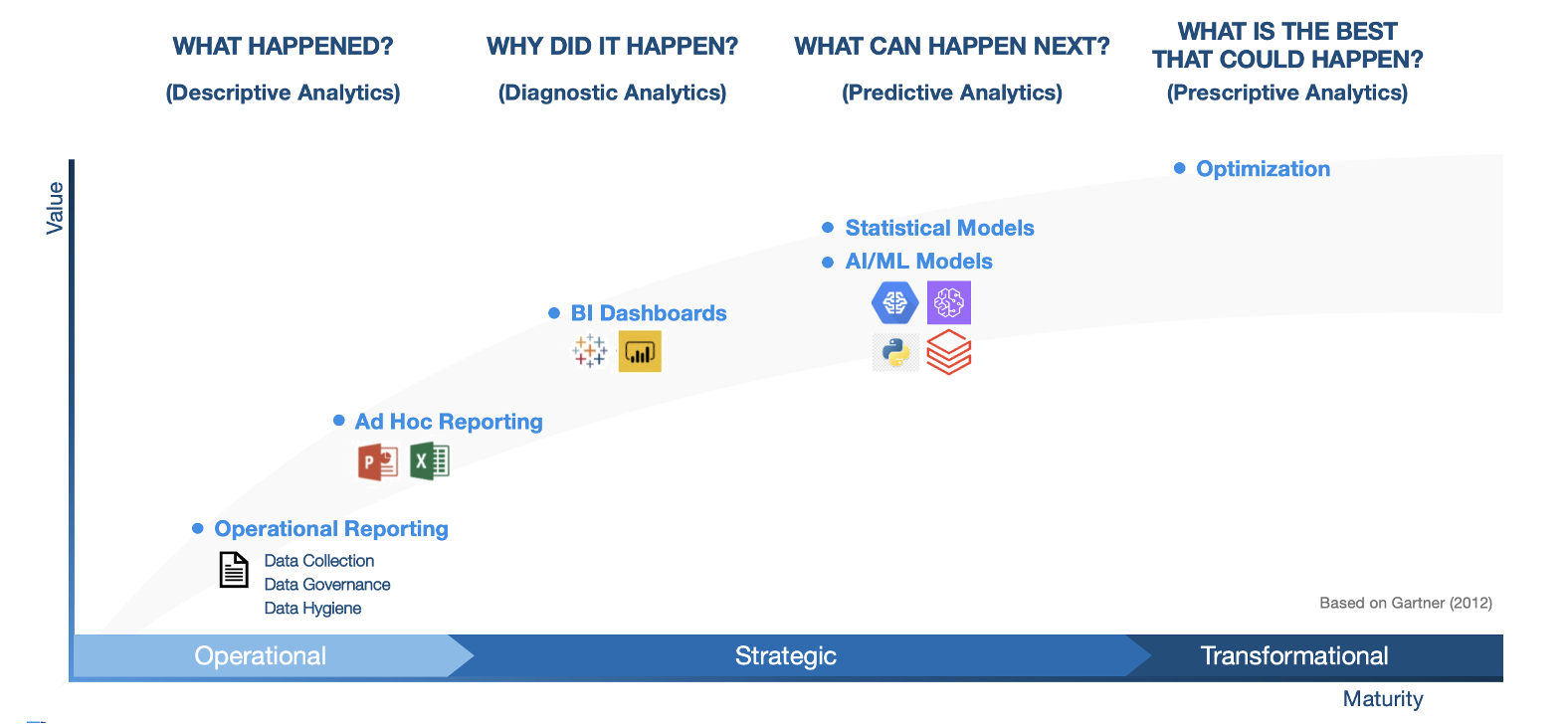
Figure 3: The Analytics Maturity Journey
It is important to note here that as an organization embarks on this maturity journey, it is not necessary to be at the end stage before it can start extracting benefits from the data. For example, it may be possible to run predictive analysis on a subset of the data even when at an earlier stage of maturity. In fact, it may be argued that this journey will never end, as an organization will need to adapt continuously to new challenges in its business environment.
Descriptive Analytics
The data journey must be built upon a solid foundation of data collection & integration, data hygiene, and data governance. Without this foundation, it is impossible to build a mature analytics pipeline.
Once the foundation is established, an organization is ready to enter the “Descriptive Analytics” stage, in which operational and ad-hoc reports can be created to answer questions such as, “What Happened?”. These reports are typically static in nature and produced as part of batch jobs by standard reporting tools. Tools like Microsoft Excel, with its pivot table and VLOOKUP capabilities, are also great tools for data exploration.
Diagnostic Analytics
The second stage of data maturity is called “Diagnostic Analytics.” At this stage, an organization can answer questions such as, “Why did Something Happen?”. Interactive dashboards using visualization tools like Tableau or Power BI can depict data graphically and allow users to summarize a lot of data quickly and explore the data to understand what is behind the numbers.
For example, organizations in consumer-oriented businesses like retail, finance, and health care can leverage visualization outputs to enable product and services personalization for customers.
Predictive Analytics
As an organization evolves to the stage of “Predictive Analytics,” it is transitioning from an operational to a strategic posture. The organization can now begin to build forward-looking models to ask questions like, “What can Happen Next?”. Organizations can utilize sophisticated statistical and ML modeling techniques to identify patterns and relationships from the data, and start predicting trends.
As examples, predictive analytics can help identify and categorize customers based on risk, profitability, or purchasing patterns, or identify fraud from anomalous transactions data.
Prescriptive Analytics
The final stage in the data maturity journey is that of Prescriptive Analytics. At this stage, the system can tell the organization, “What is the Best Outcome Possible?”. At this juncture, the data pipeline can help the organization optimize outcomes like revenue or profitability. This can lead to truly transformational change in how analytics becomes a natural part of the business.
Examples of such strategic optimizations in industries such as retail and manufacturing are streamlining operations, logistics and supply-chain in real time, or anticipatory resource scheduling across multiple locations.

Building the Data and Analytics Operating Model (D&AOM)
A robust but flexible data and analytics operating model should not only support an organization’s current needs, but also be adaptive enough for new strategic directions and technological changes. To be effective, the model must accommodate existing organizational and technological capabilities and resources as much as possible.
The high-level steps for building a Data and Analytics Operating Model are:

Figure 4: Phases in Building a Data & Analytics Operating Model
Discover Phase
For any organization, the Discover Phase is critical to understanding and identifying the strategic imperatives of the business: “How will data and analytics be used to drive insights and value?”. The answers to this question will inform the D&AOM design and architecture.
The three key influences on the D&AOM design are:
Internal: related to the organization itself
External: related to outside influences acting on the organization
Foundational: related to all the factors that will impact the modeling initiative
Figure 5 below lists the various components of these three categories.

Figure 5: Discover Phase Components
Assess Phase
The Assess Phase helps define the Data Business Model and the Data Operating Model. The Data Business Model identifies all the core processes, both internal and external, that generate or consume data, across the entire data value chain. The Data Operating Model touches all aspects of integrations across these processes and helps identify the key technology and governance gaps across the data landscape.

Figure 6: Assess Phase Components
Roadmap Phase
The Roadmap Phase contains both a standardization and a planning step. Standardization is key to ensuring data can flow consistently across systems, irrespective of its format or origin.

Figure 7: Roadmap Phase Components
This step also identifies the key components of the Reference D&AOM, shown below, as it serves as the basis for planning and creating a roadmap.

Figure 8: Reference Data and Operating Model
The Reference D&AOM is like any other operating model but from the perspective of data. For example, for the components listed in Figure 8:
Manage Process: enables end-to-end integration of the worlds of business and data
Manage Data & Analytics Services: responsible for all aspects of data governance and management, from acquisition, processing, reporting, and analytics
Manage Project Lifecycle: manages data-oriented projects, utilizing standard project management tools and techniques
Manage Technology/Platform: addresses all aspects of technology—architecture, infrastructure, applications—and the related support and change management
The road-mapping activity which follows the standardization step should subscribe to an agile approach of use-case creation, prioritization, and iteration planning, making sure that high-value items are prioritized and represented at the top of the backlog.
The business use cases that are identified in the “Use case creation and prioritization” step can be grouped into the broad categories identified in the Discover Phase:
Internal use-cases focused on internal business process optimizations
External use-cases focused on customer-facing areas like pricing, growth, customer satisfaction and churn, effectiveness of marketing spend etc.
Foundational use-cases focused on areas like predictive maintenance, IT demand and cost optimizations, fraud detection etc.
The overall project plan should be grounded in the big picture, while delivering value continuously through short- and medium-term goals. This is critical because the sooner the organization can extract value out of the data model, the easier it justifies the cost of this effort. It is important to first identify the business use cases that an organization will get value out of and then think of the data and effort to operationalize them.
Execute Phase
The execution phase follows naturally from the agile planning phase, with iterative projects that focus on outcomes, not operations, and a “fail-fast” and “test and learn” mindset that is critical for success.

Figure 9: Iterative Execute Phase
Each project should focus on delivering a capability with a well-defined business value. Iterative value delivery combined with the outputs of the Discover and Assess phases, should help to mitigate the risks and challenges previously discussed in the data space. However, risks and impediments should be reassessed as projects progress, to help empirically assess and address their impact.
Conclusion
The data domain is accelerating. Given the sheer amount of data generated, the importance of learning how to utilize the information available to an organization must become an imperative. It is essential to upskill oneself, and one’s organization and team in the data domain to not be left behind. Harnessing the capabilities of a mature data and analytics practice will allow organizations to create significant value and differentiate themselves from their competitors.
For an organization to become truly data-driven, and to speak the language of analytics in its day-to-day operations, the entire organization must commit to the journey, adopt an agile mindset, and bridge the gap between technology and business.
Though there is no one-size-fits-all approach, the above framework can help an organization build a robust and adaptable D&AOM, which can provide consistency in approach and shared understanding to foster data competency. The framework helps tie the D&AOM to the big picture strategic imperatives, and at the same time, smaller iterative wins help to build momentum and expose the possibilities which greater data maturity will bring.
Authors
Ranjan Bhattacharya – Chief Digital Officer
Ranjan is passionate about building technology solutions aligned with business needs, intersecting data, platform, and cloud. He is a believer in delivering value incrementally through agile processes incorporating early user feedback. Outside of technology, Ranjan loves to read widely, listen to music, and travel. Ranjan has a BS in Electrical Engineering, and an MS in Computer Science from the Indian Institute of Technology, Kharagpur, India.
Julian Flaks– Chief Technology Officer
Julian is a relentless problem solver and hoarder of full stack expertise. Having thrown himself headlong into Internet technology when best practices had barely begun to emerge, Julian is happiest putting his experience to use unlocking business value. Julian holds a Bachelor’s of Laws from The University of Wolverhampton, England and a Master of Science in Software Engineering from The University of Westminster.
Anne Lewson – Principal Consultant | Project & Program Management Leader
Anne blends technical with practical approaches to deliver projects ranging from large data mergers to more detailed, analytical solutions for a wide array of internal and external stakeholders. Anne leads the project management practice by using an applied Agile methodology suited to our clients' requirements. Anne has a B.S. in Computer Technology/Computer Systems Technology from University of Nantes and has her PMP and PMI-Agile certification.
Mark Hewitt – President & CEO
Mark is a driven leader that thinks strategically and isn’t afraid to roll up his sleeves and get to work. He believes collaboration, communication, and unwavering ethics are the cornerstones of building and evolving leading teams. Prior to joining EQengineered, Mark worked in various management and sales leadership capacities at companies including Forrester Research, Collaborative Consulting, Cantina Consulting and Molecular | Isobar. Mark is a graduate of the United States Military Academy and served in the US Army.